I’ve been working on a few projects recently that have in one way or another required the leaking of routes between different routing tables / routing instances. When I first started working with Junos I did find RIB groups a bit confusing, so here goes with a post about the feature.
In this post I’m going to show you three ways to leak routes between tables – using RIB groups, Instance Import and Logical Tunnels.
Lab topology
In this post I will re-use the topology I created in my last vMX post.
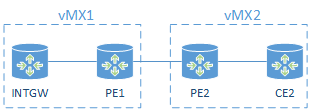
The topology consists of 2 x vMX, PE1 and PE2 will be the main routers on each vMX, and INTGW and CE2 will be Logical Systems.
The link between PE2 and CE2 will be via a VRF routing-instance “red”. All other routes are in table inet.0.
The object of the lab is to leak routes between inet.0 and red.inet.0 on PE2. We will leak a default route between inet.0 and red.inet.0 and leak CE2’s loopback in to inet.0
First let’s setup the topology…
INTGW
This device is simulating an Internet gateway. I will originate a default route in IS-IS to the rest of the topology.
Note: the Loopback address is not advertised in to IS-IS.
root@PE1> show configuration logical-systems INTGW
interfaces {
ge-0/0/2 {
unit 0 {
family inet {
address 192.168.12.1/24;
}
family iso;
}
}
lo0 {
unit 1 {
family inet {
address 1.1.1.1/32;
}
family iso {
address 49.0001.0001.0001.0001.00;
}
}
}
}
protocols {
isis {
export DEFAULT;
interface ge-0/0/2.0 {
point-to-point;
level 1 disable;
}
}
}
policy-options {
policy-statement DEFAULT {
from {
protocol aggregate;
route-filter 0.0.0.0/0 exact;
}
then accept;
}
}
routing-options {
aggregate {
route 0.0.0.0/0;
}
}
PE1
This router really isn’t doing much of interest. It is simply running IS-IS on the interfaces between INTGW and PE2
PE2
This router is learning routes from INTGW and PE2 via IS-IS. The interface connection to CE2 is placed in a routing-instance “red”. PE2 and CE2 are exchanging routes using OSPF.
interfaces {
ge-0/0/1 {
unit 0 {
family inet {
address 192.168.34.3/24;
}
}
}
}
routing-instances {
red {
instance-type virtual-router;
interface ge-0/0/1.0;
protocols {
ospf {
area 0.0.0.0 {
interface ge-0/0/1.0;
}
}
}
}
}
CE2
Nothing special about CE2.
interfaces {
ge-0/0/2 {
unit 0 {
family inet {
address 192.168.34.4/24;
}
}
}
lo0 {
unit 4 {
family inet {
address 4.4.4.4/32;
}
}
}
}
protocols {
ospf {
area 0.0.0.0 {
interface ge-0/0/2.0;
interface lo0.4 {
passive;
}
}
}
}
Objective
Our objective to to be able to to ping the Loopback address on INTGW from CE2. I am not advertising the address in to IS-IS so reachability is achieved via the default route.
root@PE2> show route 0.0.0.0
inet.0: 7 destinations, 7 routes (7 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
0.0.0.0/0 *[IS-IS/165] 01:31:47, metric 30
> to 192.168.23.2 via ge-0/0/3.0
root@PE2> show route 1.1.1.1/32
root@PE2> ping rapid count 1 1.1.1.1
PING 1.1.1.1 (1.1.1.1): 56 data bytes
!
--- 1.1.1.1 ping statistics ---
1 packets transmitted, 1 packets received, 0% packet loss
round-trip min/avg/max/stddev = 3.370/3.370/3.370/nan ms
root@PE2>
If we take a look at INTGW and CE2, neither will currently have reachability to one another.
INTGW:
root@PE1:INTGW> ping rapid count 1 4.4.4.4
PING 4.4.4.4 (4.4.4.4): 56 data bytes
ping: sendto: No route to host
.
--- 4.4.4.4 ping statistics ---
1 packets transmitted, 0 packets received, 100% packet loss
CE2:
root@PE2:CE2> ping rapid count 1 1.1.1.1
PING 1.1.1.1 (1.1.1.1): 56 data bytes
ping: sendto: No route to host
.
--- 1.1.1.1 ping statistics ---
1 packets transmitted, 0 packets received, 100% packet loss
RIB Groups
First of all I will go though how to accomplish the objective with RIB Groups alone.
Essentially a RIB group will allow you to take a route that would be normally be destined for one table, e.g. inet.0, and place that route in another table also, e.g. red.inet.0. This can be done for static, connected, or dynamic routing.
A rib-group is created as below
routing-options {
rib-groups {
INET0_to_RED {
import-rib [ inet.0 red.inet.0 ];
}
}
}
Note: the first entry after import-rib is not where we are pulling the routes from, it is where the route would normally be placed.
This config is simply stating any routes that would normally be placed in inet.0 should also be placed in red.inet.0.
However, creating the rib-group alone will not achieve anything – the rib-group must be applied elsewhere in the configuration. You have several options depending on what you want to do:
- Interface routes – set routing-options interface-routes rib-group <name>
- Static routes – set routing-options rib-group <name>
- Dynamic routes, these are applied per protocol, e.g. set protocols ospf rib-group <name>
For this lab we’ll be leaking the IS-IS routes, so I apply the rib-group to IS-IS. Remember as I am leaking routes from inet.0 to red.inet.0 I must apply the rib-group in the master config, not under the routing instance.
The rib-group is applied in to the table where the routes would normally be placed.
set protocols isis rib-group inet INET0_to_RED
Now let’s take a look in the red.inet.0 table, do we see the routes?
root@PE2> show route table red.inet.0
red.inet.0: 7 destinations, 7 routes (7 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
0.0.0.0/0 *[IS-IS/165] 05:05:37, metric 30
> to 192.168.23.2 via ge-0/0/3.0
2.2.2.2/32 *[IS-IS/18] 05:05:37, metric 10
> to 192.168.23.2 via ge-0/0/3.0
4.4.4.4/32 *[OSPF/10] 06:20:33, metric 1
> to 192.168.34.4 via ge-0/0/1.0
192.168.12.0/24 *[IS-IS/18] 05:05:37, metric 20
> to 192.168.23.2 via ge-0/0/3.0
192.168.34.0/24 *[Direct/0] 06:20:48
> via ge-0/0/1.0
192.168.34.3/32 *[Local/0] 06:20:48
Local via ge-0/0/1.0
224.0.0.5/32 *[OSPF/10] 06:20:48, metric 1
MultiRecv
Awesome! The IS-IS routes are there – we can see the default route and also the loopback on PE1. But what if we wanted to leak the default only? Junos has that covered with an import policy.
I’ll create a policy to accept the default only and apply that to the rib-group.
Just a quick note on the import policy – as IS-IS has a default import policy of accept, I need to add a final term to reject otherwise I will match everything! See this Juniper doc for a reminder of the default import/export policies for the various routing protocols.
policy-options {
policy-statement DEFAULT {
term t1 {
from {
route-filter 0.0.0.0/0 exact;
}
then accept;
}
term t2 {
then reject;
}
}
}
rib-groups {
INET0_to_RED {
import-rib [ inet.0 red.inet.0 ];
import-policy DEFAULT;
}
}
Now the routing table only has the default route leaked!
root@PE2> show route table red.inet.0
red.inet.0: 5 destinations, 5 routes (5 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
0.0.0.0/0 *[IS-IS/165] 00:04:57, metric 30
> to 192.168.23.2 via ge-0/0/3.0
4.4.4.4/32 *[OSPF/10] 06:46:46, metric 1
> to 192.168.34.4 via ge-0/0/1.0
192.168.34.0/24 *[Direct/0] 06:47:01
> via ge-0/0/1.0
192.168.34.3/32 *[Local/0] 06:47:01
Local via ge-0/0/1.0
224.0.0.5/32 *[OSPF/10] 06:47:01, metric 1
MultiRecv
Cool, so at this point the red routing-instance now has a default, but what about CE2, can that see the default?
root@PE2> show route logical-system CE2
inet.0: 4 destinations, 4 routes (4 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
4.4.4.4/32 *[Direct/0] 06:50:16
> via lo0.4
192.168.34.0/24 *[Direct/0] 06:53:12
> via ge-0/0/2.0
192.168.34.4/32 *[Local/0] 06:53:12
Local via ge-0/0/2.0
224.0.0.5/32 *[OSPF/10] 06:51:52, metric 1
MultiRecv
No default route there! Well I purposely made my life difficult by running a different protocol between PE2 and CE2. Remember PE1 and PE2 are talking IS-IS, but PE2 and CE2 are talking OSPF. So whilst the IS-IS route is now in the red.inet.0 table, we need to create an export policy to redistribute the IS-IS route over to CE2 via OSPF. The export policy is applied to the routing-instance.
Note this time my policy does not need an explicit reject to be configured as the default export policy for OSPF is reject.
policy-options {
policy-statement FROM_ISIS {
from protocol isis;
then accept;
}
}
The export policy is applied to the routing-instance.
set routing-instances red protocols ospf export FROM_ISIS
Now we have an OSPF external default route present on CE2.
root@PE2> show route logical-system CE2
inet.0: 5 destinations, 5 routes (5 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
0.0.0.0/0 *[OSPF/150] 00:00:02, metric 30, tag 0
> to 192.168.34.3 via ge-0/0/2.0
4.4.4.4/32 *[Direct/0] 06:55:43
> via lo0.4
192.168.34.0/24 *[Direct/0] 06:58:39
> via ge-0/0/2.0
192.168.34.4/32 *[Local/0] 06:58:39
Local via ge-0/0/2.0
224.0.0.5/32 *[OSPF/10] 06:57:19, metric 1
MultiRecv
Great, so CE2 knows how to route to INTGW via the default, but INTGW will not know how to route back at this point. I could do NAT on PE2 to hide the address of CE2, or repeat the rib-group process but this time to leak routes from red.inet.0 to inet.0 on PE2. We’ll do it with a rib-group.
root@PE2# show | compare
[edit routing-options rib-groups]
+ RED_to_INET0 {
+ import-rib [ red.inet.0 inet.0 ];
+ }
[edit routing-instances red protocols ospf]
+ rib-group RED_to_INET0;
[edit policy-options]
+ policy-statement FROM_OSPF {
+ from {
+ protocol ospf;
+ route-filter 4.4.4.4/32 exact;
+ }
+
[edit protocols isis]
+ export [ FROM_OSPF ];
Notice this time that the order of the import-rib has changed. We are copying routes from red.inet.0, as this is where the routes would normally be placed so red.inet.0 is the first entry in the import-rib statement. This also reminds us where to apply the rib-group.
The rib-group is applied to the routing-instance OSPF process, and again we must export the OSPF routes to IS-IS. Note this export is applied to the master IS-IS process, not the routing instance.
root@INTGW> show route table inet.0 0.0.0.0/0 exact
inet.0: 9 destinations, 9 routes (9 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
0.0.0.0/0 *[IS-IS/165] 09:12:27, metric 20
> to 192.168.12.1 via ge-0/0/1.0
At this point we should have reachability between CE2 and INTGW.
root@PE2> ping 1.1.1.1 source 4.4.4.4 rapid logical-system CE2
PING 1.1.1.1 (1.1.1.1): 56 data bytes
!!!!!
--- 1.1.1.1 ping statistics ---
5 packets transmitted, 5 packets received, 0% packet loss
round-trip min/avg/max/stddev = 3.890/4.173/4.364/0.181 ms
Success !
Instance Import
Now to repeat this again, but this time using instance import! I’ll start by clearing out the rib-groups.
delete routing-options rib-groups INET0_to_RED
delete routing-options rib-groups RED_to_INET0
delete protocols isis rib-group inet INET0_to_RED
delete routing-instances red protocols ospf rib-group RED_to_INET0
First of all I’ll create a policy to import routes from inet.0 to red.inet.0
policy-options {
policy-statement FROM_GLOBAL {
term t1 {
from {
instance master;
route-filter 0.0.0.0/0 exact;
}
then accept;
}
term t2 {
then reject;
}
}
}
This policy is simply saying for a default route in the master inet.0 table then accept for import and deny everything else. We then apply this policy to the red routing-instance.
set routing-instances red routing-options instance-import FROM_GLOBAL
Now the policy has been configured, table red.inet.0 has a default route imported from the master instance. Since I left the IS-IS to OSPF export in place from the previous rib-group exercise, CE2 will also have the default route.
root@PE2> show route table red.inet.0 0.0.0.0
red.inet.0: 5 destinations, 5 routes (5 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
0.0.0.0/0 *[IS-IS/165] 00:06:22, metric 30
> to 192.168.23.2 via ge-0/0/3.0
root@PE2> show route 0.0.0.0 logical-system CE2
inet.0: 5 destinations, 5 routes (5 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
0.0.0.0/0 *[OSPF/150] 00:06:29, metric 30, tag 0
> to 192.168.34.3 via ge-0/0/2.0
I now need to leak the CE2 loopback IP between the red.inet.0 table and the master inet.0 table. Again this is a simple routing policy that is applied to the master routing-options.
routing-options {
instance-import FROM_RED;
}
policy-options {
policy-statement FROM_RED {
term t1 {
from {
instance red;
route-filter 4.4.4.4/32 exact;
}
then accept;
}
term t2 {
then reject;
}
}
}
As the OSPF to IS-IS exports were left in place from the rib-group exercise, INTGW should now have the 4.4.4.4/32 route, and it does.
root@PE1> show route 4.4.4.4/32 logical-system INTGW
inet.0: 8 destinations, 8 routes (8 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
4.4.4.4/32 *[IS-IS/165] 00:02:54, metric 21
> to 192.168.12.2 via ge-0/0/2.0
Verification – can I ping from CE2 to INTGW, yes!
root@PE2> ping 1.1.1.1 rapid source 4.4.4.4 logical-system CE2
PING 1.1.1.1 (1.1.1.1): 56 data bytes
!!!!!
--- 1.1.1.1 ping statistics ---
5 packets transmitted, 5 packets received, 0% packet loss
round-trip min/avg/max/stddev = 3.879/8.912/24.706/8.031 ms
Using the instance-import feature is perhaps a little more intuitive than rib-groups, although both can achieve the same end result.
Logical Tunnel
A final way of doing the leaking is to use Logical Tunnel interfaces. The configuration is very simple – an LT is created with one end of the tunnel in the master inet.0 table, and the other end added to red routing instance. We then simply run a routing protocol or static routing via the tunnel interface.
First of all we create the tunnel interfaces and assign one side to the correct routing instance. This is a vMX so I also need to enable the tunnel services.
chassis {
fpc 0 {
pic 0 {
tunnel-services;
}
}
}
interfaces {
lt-0/0/0 {
unit 0 {
encapsulation ethernet;
peer-unit 1;
family inet {
address 10.0.0.1/24;
}
}
unit 1 {
encapsulation ethernet;
peer-unit 0;
family inet {
address 10.0.0.2/24;
}
}
}
}
routing-instances {
red {
interface lt-0/0/0.1;
}
}
}
From here, it’s a simple matter of running a routing protocol via the tunnel. As my red routing-instance is using OSPF routing with CE2, I configure the LT interfaces in OSPF within the master config and the routing-instance.
Note, because I’m running IS-IS between PE1 and PE2, on PE2 I’m also redistributing IS-IS routes to OSPF and OSPF routes to IS-IS to provide reachability.
root@PE2# show | compare
[edit protocols]
+ ospf {
+ export FROM_ISIS;
+ area 0.0.0.0 {
+ interface lt-0/0/0.0;
+ }
+ }
+ isis {
+ export FROM_OSPF;
+ }
[edit routing-instances red protocols ospf area 0.0.0.0]
+ interface lt-0/0/0.1;
root@PE2> show route logical-system CE2 0.0.0.0
inet.0: 8 destinations, 8 routes (8 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
0.0.0.0/0 *[OSPF/150] 00:06:42, metric 30, tag 0
> to 192.168.34.3 via ge-0/0/2.0
root@PE1> show route table inet.0 4.4.4.4
inet.0: 9 destinations, 9 routes (9 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
4.4.4.4/32 *[IS-IS/165] 00:07:08, metric 12
> to 192.168.23.3 via ge-0/0/3.0
Can I ping from CE2 to INTGW – yes!
root@PE2# run ping 1.1.1.1 source 4.4.4.4 rapid logical-system CE2
PING 1.1.1.1 (1.1.1.1): 56 data bytes
!!!!!
--- 1.1.1.1 ping statistics ---
5 packets transmitted, 5 packets received, 0% packet loss
round-trip min/avg/max/stddev = 3.330/3.609/3.884/0.213 ms
Conclusion
I’ve shown three way to leak routes between routing tables on Junos. There are of course many other ways of doing this – static route with next-table, or if I was running MPLS VPNs in this lab I’d also have route-targets to play with, or the auto-export feature for prefix leaking between local VRFs.
If you would like to see a post about these other methods, please say so in the comments. Thanks for reading this post 🙂